Social media sites have been under fire recently for spreading false information and allowing online toxicity to thrive. A recent Senate judiciary subcommittee hearing targeted Facebook, Twitter, and Google for hours of testimony on Russian interference in the 2016 election. In the aftermath, Facebook has been hard at work repairing its image and enhancing its technology to keep up with the high expectations of the public.
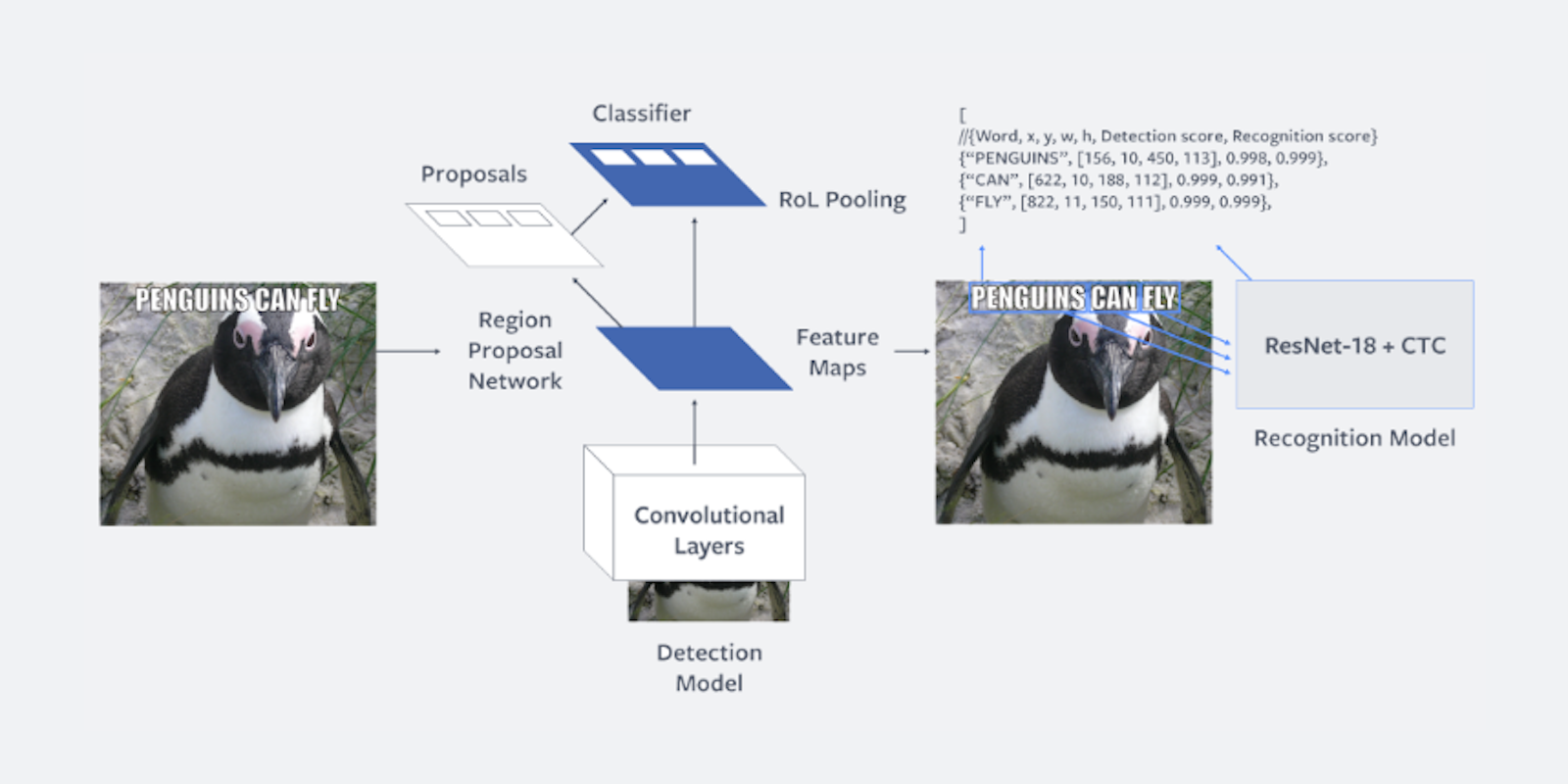
Facebook’s newest advancement relates to memes. These amusing images usually sport accompanying text, which cannot be caught by most profanity filters. That is not to mention posted photos or digitally altered images that contain text on signs, posters, or pieces of paper. Enter Rosetta, a “large-scale machine learning system” that is capable of extracting text from billions of posts—in dozens of different languages—on Facebook and Instagram in real time, and inputting it into a text recognition model.
Rosetta’s text recognition model has been “trained on classifiers to understand the context of the text and the image together,” according to Facebook. This means that it can pair the text with the accompanying image to identify potentially false, inflammatory, or toxic content. Tools that can transcribe text are nothing new, but the sheer volume of Facebook’s content presents a unique challenge. According to the company post that announced Rosetta, the system is already in action.
Facebook did not go into detail regarding its long-term goals with this technology. It plans to employ the AI to ease the process of searching images, to better identify content that violates Facebook’s hate-speech policy, and to enhance the personalization of news feeds. In the future, the hope is to use a similar technology on video content. The current method of extracting text from videos involves examining each frame individually—a daunting task for such a massive platform.
For the time being, Facebook is sticking with the challenge of extracting information from billions of shared images every day. Considering moderation issues in the past, this should be a step in the right direction, particularly if it eases the process of searching those difficult-to-find images and perusing Facebook timelines.
H/T the Verge

