Woody’s “bald ass” is the obvious star of “Toy Story 5” so far. It’s already a meme
The OG fans are feeling old.



The Latest
See all posts“Weirdly unique”: Imagine Dragons frontman Dan Reynolds spent years turning Capture the Flag into a new video game
"Dan Reynolds building games? Love the creator vibe CTF with fresh twists and original tunes hits right."
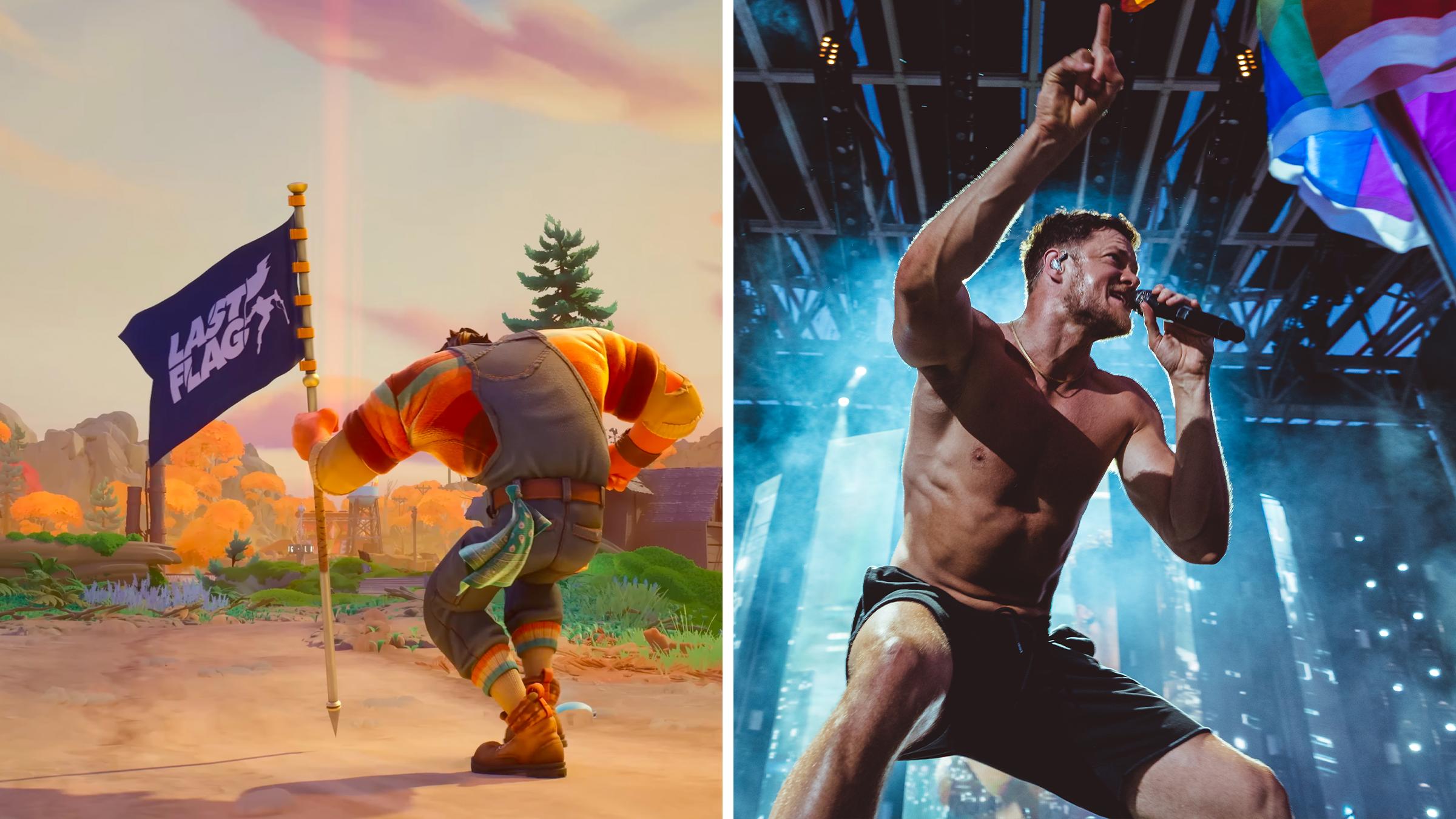
“Nature sure is POWERFUL”: Social media tributes pour in after Iceland’s famous black sand beaches are swept out to sea
Mother Nature took back Iceland's beloved Reynisfjara black sand beach.

Eric Dane’s final interview comes from a controversial new Netflix docuseries called “Famous Last Words”
"There’s something powerful about choosing dignity as your final lesson to your children."

AJ and Big Justice respond to lighthearted criticism of giving “5 booms” to a dead man
"This is the very first time I’m addressing it..."

“You’ll lose me as a customer”: Norwegian Cruise Line fans are pissed over dining dress code change
If you don't like it, go to Disney.

“JAIL!!!”: Influencer’s disturbing hotel coffee maker “hack” has viewers horrified
"I don't ever drink from the hotel room coffee makers since learning people do this ?"

The first look at Apple TV’s adaptation of “Imperfect Women” is here, and fans of the book can’t wait
The trailer brought comparisons to a more adult "Pretty Little Liars."

Entertainment
“Oh my jeepers”: Mckenna Grace cast as Daphne in the next live-action “Scooby-Doo” movie
A full circle moment.

Ben Schwartz welcomes Kristen Bell to the “Sonic” cast, where she’ll be playing Amy Rose
Sonic 4 has found its Amy Rose... Kristen Bell!

“Tell Me Lies” fans discover the show won’t be returning for a fourth season right before its third finale dropped
Fans were not prepared for the show to end.

After his role as JFK Jr. in “Love Story,” Batman fans want Paul Anthony Kelly to play Bruce Wayne next
"Paul Anthony Kelly actually has the look for Bruce Wayne."

Viral Politics
JD Vance says he would “prefer” Eileen Gu represent the U.S. instead of China, sparking a fresh wave of backlash towards the athlete
The Olympian just revealed she was harassed and had her dorm robbed over her decision.

“Beyond parody”: The internet can’t process RFK Jr and Kid Rock’s jeans-on, milk-drinking workout video
"I cannot possibly imagine two men I’d like to take health advice from less."

“FCC you”: Stephen Colbert posts interview CBS axed after FCC threats. Here it is
"Because my network clearly doesn’t want us to talk about this, let’s talk about this."

“They’re real”: Obama says aliens exist and UFO truthers lose their minds
"2026 is absolutely unhinged."

Memes
What exactly is “the French show with the good lighting” that everyone is raving about?
"How do I get a ring light with same lighting as the french show with good lighting?"

Team USA defenseman Quinn Hughes goes viral for his expressions: “Haunted by the ghost of a Victorian child”
"Why would they let Quinn Hughes go to an old, historic place like Italy? He’s going to bring back so many ghosts."


Curling fans accuse Canadian player of cheating at the Olympics. The memes are merciless
POV: you are a curling team playing against Canadians.

Trending
Burger King just gave customers its president’s phone number to call with complaints. Yes, seriously
The King's personal line is open.

“Actually speechless”: Dentist spends 90 minutes fighting insurance over denied claim. Then the rep says this
"Why do insurance companies get to tell doctors how they have to do their jobs?"

“Reese’s identity is being rewritten:” Grandson of Reese’s Peanut Butter Cups inventor slams Hershey for making the candy “inedible”
"So that's why it doesn't taste the same anymore."

“Route paused, hearts melted”: UPS drivers are posting the cutest dogs along their delivery routes on Facebook
"There’s no views of what people think about this or that, just dogs and an occasional cat, donkey, turtle or bird."

Tech
“World of Warcraft” partners with Zillow to promote new in-game homes. Players’ reactions are mixed
"How did I end up in this timeline?"

“Repulsive and immoral”: Backlash grows after Meta obtains patent for AI bots to take over a dead user’s account
"Why would anyone ever want this?"

“Thank you for your patience”: TeamSpeak’s servers reach capacity after Discord users flee age verification policy
"The end is near."

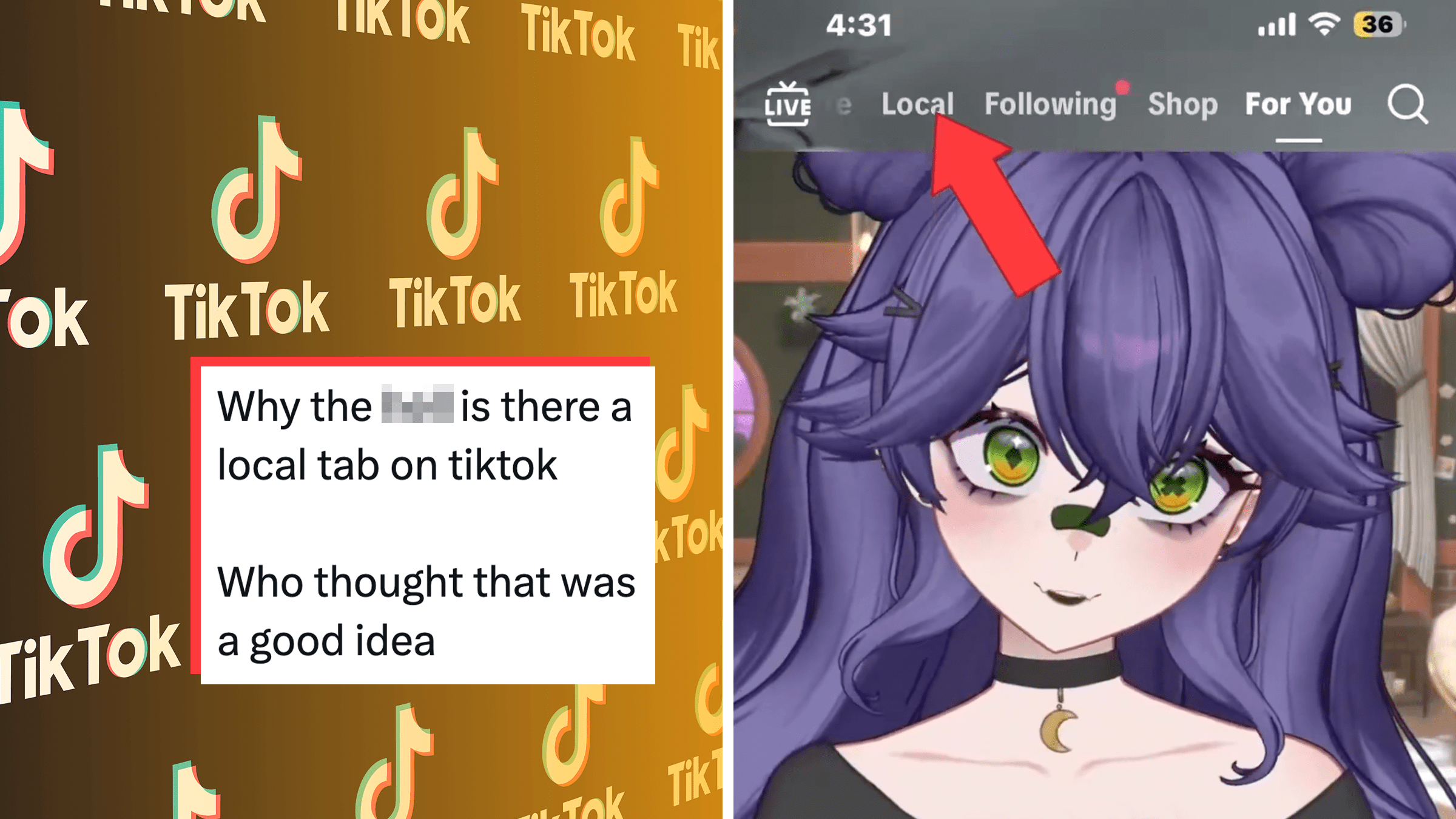
“Essentially doxxing folks”: TikTok’s new “Local Feed” sparks more privacy concerns and opt-out confusion
“This is the most dangerous feature I've ever seen."
Culture
Steam Deck suddenly goes out of stock. Gamers blame AI
"In 10 years we're legit going to be making Frankenstein monster PCS just to play Stardew Valley."

Beauty influencer’s glitch exposes her real face, causing her to lose 140K followers
"She is actually very beautiful."

Men are proudly eating “boy kibble,” their ultra-bland ultra-protein answer to “girl dinner”
"A bowl of white rice and ground beef at 8pm+ hits different."

Draco Malfoy is the surprising new mascot for China’s Lunar New Year—and Tom Felton can’t get enough
Ironic that one of the villains of the franchise would have such a large and positive resurgence.

TikTok
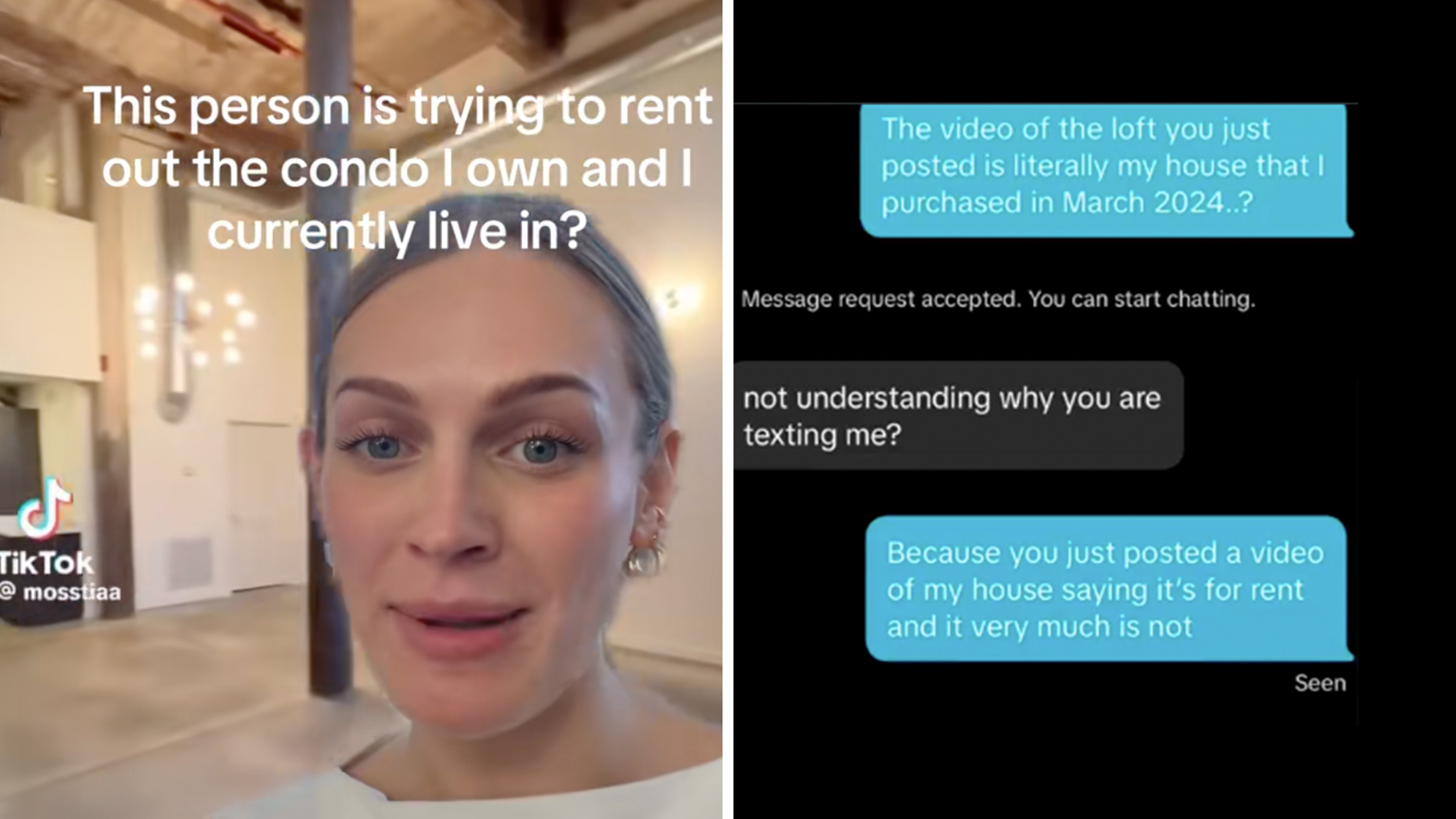
“Girl that’s all on you”: Homeowner posts “proof” of bad Amazon driver—it quickly backfires
"You gave us video evidence on why we shouldn't side with you."

“Am I delusional?”: Woman suspects she was kidnapped after discovering disturbing inconsistencies in her birth story
Her story has been viewed over 6 million times.

“My husband thought I was crazy”: Woman hears strange noises in her couch. Then she looks inside
Where can I buy a couch like this?